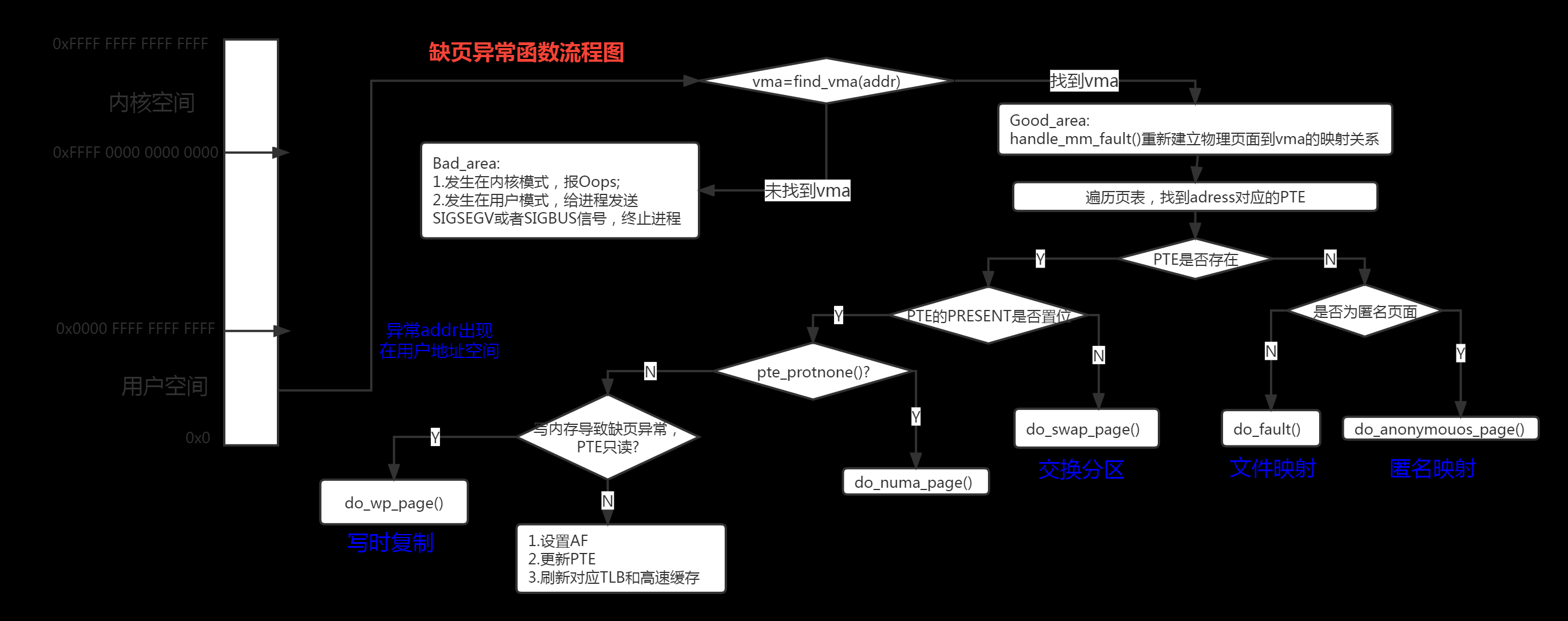
staticint __kprobes do_page_fault(unsignedlong far, unsignedint esr, struct pt_regs *regs) { conststructfault_info *inf; structmm_struct *mm = current->mm; vm_fault_t fault; unsignedlong vm_flags; unsignedint mm_flags = FAULT_FLAG_DEFAULT; unsignedlong addr = untagged_addr(far); if (kprobe_page_fault(regs, esr)) return0; /* * If we're in an interrupt or have no user context, we must not take * the fault. *//// 检查异常发生时的路径, 若不合条件,直接跳转 no_context,出错处理 if (faulthandler_disabled() || !mm) /// 是否关闭缺页中断,是否在中断上下文,是否内核空间,内核进程的 mm 总是 NULL goto no_context; if (user_mode(regs)) mm_flags |= FAULT_FLAG_USER; /* * vm_flags tells us what bits we must have in vma->vm_flags * for the fault to be benign, __do_page_fault() would check * vma->vm_flags & vm_flags and returns an error if the * intersection is empty */ if (is_el0_instruction_abort(esr)) { /// 判断是否为低异常等级的指令异常,若为指令异常,说明该地址具有可执行权限 /* It was exec fault */ vm_flags = VM_EXEC; mm_flags |= FAULT_FLAG_INSTRUCTION; } elseif (is_write_abort(esr)) { /// 写内存区错误 /* It was write fault */ vm_flags = VM_WRITE; mm_flags |= FAULT_FLAG_WRITE; } else { /* It was read fault */ vm_flags = VM_READ; /* Write implies read */ vm_flags |= VM_WRITE; /* If EPAN is absent then exec implies read */ if (!cpus_have_const_cap(ARM64_HAS_EPAN)) vm_flags |= VM_EXEC; } /// 判断是否为用户空间,是否 EL1 权限错误,都满足时,表明处于少见的特殊情况,直接报错处理 if (is_ttbr0_addr(addr) && is_el1_permission_fault(addr, esr, regs)) {if (is_el1_instruction_abort(esr)) die_kernel_fault("execution of user memory", addr, esr, regs); if (!search_exception_tables(regs->pc)) die_kernel_fault("access to user memory outside uaccess routines", addr, esr, regs); } perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, addr); /* * As per x86, we may deadlock here. However, since the kernel only * validly references user space from well defined areas of the code, * we can bug out early if this is from code which shouldn't. *//// 执行到这里,可以断定缺页异常没有发生在中断上下文,没有发生在内核线程,以及一些特殊情况;接下来检查由于地址空间引发的缺页异常 if (!mmap_read_trylock(mm)) {if (!user_mode(regs) && !search_exception_tables(regs->pc)) goto no_context; retry: mmap_read_lock(mm); /// 睡眠,等待锁释放 } else { /* * The above mmap_read_trylock() might have succeeded in which * case, we'll have missed the might_sleep() from down_read(). */ might_sleep(); #ifdef CONFIG_DEBUG_VM if (!user_mode(regs) && !search_exception_tables(regs->pc)) {mmap_read_unlock(mm); goto no_context; } #endif } /// 进一步处理缺页以异常 fault = __do_page_fault(mm, addr, mm_flags, vm_flags, regs); ... no_context: __do_kernel_fault(addr, esr, regs); /// 报错处理 return0; }
staticvm_fault_t __do_page_fault(struct mm_struct *mm, unsignedlong addr, unsignedint mm_flags, unsignedlong vm_flags, struct pt_regs *regs) {structvm_area_struct *vma = find_vma(mm, addr); /// 查找失效地址 addr 对应的 vma if (unlikely(!vma)) /// 找不到 vma,说明 addr 还没在进程地址空间中,返回 VM_FAULT_BADMAP return VM_FAULT_BADMAP; /* * Ok, we have a good vm_area for this memory access, so we can handle * it. */ if (unlikely(vma->vm_start > addr)) {///vm_start>addr, 特殊情况(栈,向下增长),检查能否 vma 扩展到 addr,否则报错 if (!(vma->vm_flags & VM_GROWSDOWN)) return VM_FAULT_BADMAP; if (expand_stack(vma, addr)) return VM_FAULT_BADMAP; } /* * Check that the permissions on the VMA allow for the fault which * occurred. */ if (!(vma->vm_flags & vm_flags)) /// 判断 vma 属性,无权限,直接返回 return VM_FAULT_BADACCESS; return handle_mm_fault(vma, addr & PAGE_MASK, mm_flags, regs); /// 缺页中断处理的核心处理函数 }
staticvm_fault_thandle_pte_fault(struct vm_fault *vmf) { pte_t entry; if (unlikely(pmd_none(*vmf->pmd))) { /* * Leave __pte_alloc() until later: because vm_ops->fault may * want to allocate huge page, and if we expose page table * for an instant, it will be difficult to retract from * concurrent faults and from rmap lookups. */ vmf->pte = NULL; } else { /* * If a huge pmd materialized under us just retry later. Use * pmd_trans_unstable() via pmd_devmap_trans_unstable() instead * of pmd_trans_huge() to ensure the pmd didn't become * pmd_trans_huge under us and then back to pmd_none, as a * result of MADV_DONTNEED running immediately after a huge pmd * fault in a different thread of this mm, in turn leading to a * misleading pmd_trans_huge() retval. All we have to ensure is * that it is a regular pmd that we can walk with * pte_offset_map() and we can do that through an atomic read * in C, which is what pmd_trans_unstable() provides. */ if (pmd_devmap_trans_unstable(vmf->pmd)) return0; /* * A regular pmd is established and it can't morph into a huge * pmd from under us anymore at this point because we hold the * mmap_lock read mode and khugepaged takes it in write mode. * So now it's safe to run pte_offset_map(). */ vmf->pte = pte_offset_map(vmf->pmd, vmf->address); /// 计算 pte 页表项 vmf->orig_pte = *vmf->pte; /// 读取 pte 内容到 vmf->orig_pte /* * some architectures can have larger ptes than wordsize, * e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and * CONFIG_32BIT=y, so READ_ONCE cannot guarantee atomic * accesses. The code below just needs a consistent view * for the ifs and we later double check anyway with the * ptl lock held. So here a barrier will do. */ barrier(); /// 有的处理器 PTE 会大于字长,所以 READ_ONCE()不能保证原子性,添加内存屏障以保证正确读取了 PTE 内容 if (pte_none(vmf->orig_pte)) {pte_unmap(vmf->pte); vmf->pte = NULL; } } ///pte 为空 if (!vmf->pte) {if (vma_is_anonymous(vmf->vma)) return do_anonymous_page(vmf); /// 处理匿名映射 else return do_fault(vmf); /// 文件映射 } ///pte 不为空 if (!pte_present(vmf->orig_pte)) ///pte 存在,但是不在内存中,从交换分区读回页面 return do_swap_page(vmf); if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma)) /// 处理 numa 调度页面 return do_numa_page(vmf); vmf->ptl = pte_lockptr(vmf->vma->vm_mm, vmf->pmd); spin_lock(vmf->ptl); entry = vmf->orig_pte; if (unlikely(!pte_same(*vmf->pte, entry))) {update_mmu_tlb(vmf->vma, vmf->address, vmf->pte); goto unlock; } if (vmf->flags & FAULT_FLAG_WRITE) { ///FAULT_FLAG_WRITE 标志,根据 ESR_ELx_WnR 设置 if (!pte_write(entry)) return do_wp_page(vmf); ///vma 可写,pte 只读,触发缺页异常,父子进程共享的内存,写时复制 entry = pte_mkdirty(entry); } entry = pte_mkyoung(entry); /// 访问标志位错误,设置 PTE_AF 位 if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry, /// 更新 PTE 和缓存 vmf->flags & FAULT_FLAG_WRITE)) {update_mmu_cache(vmf->vma, vmf->address, vmf->pte); } else { /* Skip spurious TLB flush for retried page fault */ if (vmf->flags & FAULT_FLAG_TRIED) goto unlock; /* * This is needed only for protection faults but the arch code * is not yet telling us if this is a protection fault or not. * This still avoids useless tlb flushes for .text page faults * with threads. */ if (vmf->flags & FAULT_FLAG_WRITE) flush_tlb_fix_spurious_fault(vmf->vma, vmf->address); } unlock: pte_unmap_unlock(vmf->pte, vmf->ptl); return0; }