

linux源码解析06–常用内存分配函数kmalloc、vmalloc、malloc和mmap实现原理
科学边界
一、kmalloc 函数
1 | static __always_inline void *kmalloc(size_t size, gfp_t flags) |
kmem_cache_alloc_trace 分配函数
1 | void * |
可见,kmalloc() 基于 slab 分配器实现,因此分配的内存,物理上都是连续的。
二、vmalloc 函数
1 | vmalloc() |
2.1 核心函数__vmalloc_node_range
1 | static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask, |
可见,vmalloc 是临时在 vmalloc 内存区申请 vma,并且分配物理页面,建立映射;直接分配物理页面,至少一个页 4K,因此 vmalloc 适合用于分配较大内存,并且物理内存不一定连续;
三、malloc 函数
malloc 是 C 库实现的函数,C 库维护了一个缓存,当内存够用时,malloc 直接从 C 库缓存分配,只有当 C 库缓存不够用;
通过系统调用 brk,向内核申请,从堆空间申请一个 vma;
malloc 实现流程图:
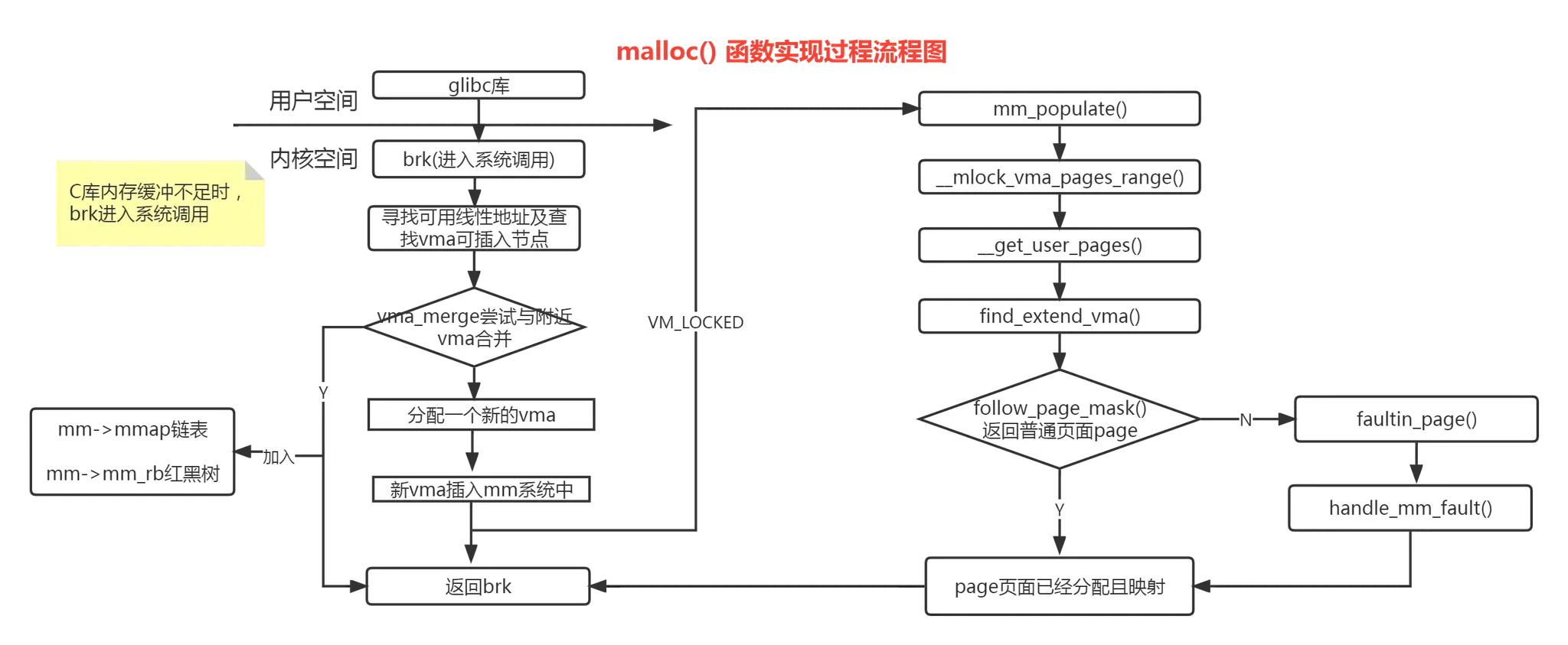
3.1 __do_sys_brk 函数
经过平台相关实现,malloc 最终会调用 SYSCALL_DEFINE1 宏,扩展为__do_sys_brk 函数
1 | SYSCALL_DEFINE1(brk, unsigned long, brk) |
总结下__do_sys_brk() 功能:
(1) 从旧的 brk 边界去查询,是否有可用 vma,若发现有重叠,直接使用;
(2) 若无发现重叠,新分配一个 vma;
(3) 应用程序若调用 mlockall(),会锁住进程所有虚拟地址空间,防止内存被交换出去,且立刻分配物理内存;否则,物理页面会等到使用时,触发缺页异常分配;
3.2 do_brk_flags 函数
函数实现:
(1) 寻找一个可使用的线性地址;
(2) 查找最适合插入红黑树的节点;
(3) 寻到的线性地址是否可以合并现有 vma,所不能,新建一个 vma;
(4) 将新建 vma 插入 mmap 链表和红黑树中
1 | /* |
3.3 mm_populate() 函数
依次调用
1 | mm_populate() |
当设置 VM_LOCKED 标志时,表示要马上申请物理页面,并与 vma 建立映射;
否则,这里不操作,直到访问该 vma 时,触发缺页异常,再分配物理页面,并建立映射;
3.3.1 __get_user_pages() 函数
1 | static long __get_user_pages(struct mm_struct *mm, |
3.1.1.1 follow_page_pte 函数
1 | static struct page *follow_page_pte(struct vm_area_struct *vma, |
总结:
- malloc 函数,从 C 库缓存分配内存,其分配或释放内存,未必马上会执行;
- malloc 实际分配内存动作,要么主动设置 mlockall(),人为触发缺页异常,分配物理页面;或者在访问内存时触发缺页异常,分配物理页面;
- malloc 分配虚拟内存,有三种情况:
- malloc() 分配内存后,直接读,linux 内核进入缺页异常,调用 do_anonymous_page 函数使用零页映射,此时 PTE 属性只读;
- malloc() 分配内存后,先读后写,linux 内核第一次触发缺页异常,映射零页;第二次触发异常,触发写时复制;
- malloc() 分配内存后, 直接写,linux 内核进入匿名页面的缺页异常,调用 alloc_zeroed_user_highpage_movable 分配一个新页面,这个 PTE 是可写的;
4.mmap 函数
mmap 一般用于用户程序分配内存,读写大文件,链接动态库,多进程内存共享等;
实现过程流程图:

mmap 根据文件关联性和映射区域是否共享等属性,其映射分为 4 类
1. 私有匿名映射
fd=-1, 且 flags=MAP_ANONYMOUS|MAP_PRIVATE, 创建的 mmap 映射是私有匿名映射;
用途是在 glibc 分配大内存时,如果需分配内存大于 MMAP_THREASHOLD(128KB),glibc 默认用 mmap 代替 brk 分配内存;
2. 共享匿名映射
fd=-1, 且 flags=MAP_ANONYMOUS|MAP_SHARED;
常用于父子进程的通信,共享一块内存区域;
do_mmap_pgoff()->mmap_region(), 最终调用 shmem_zero_setup 打开 /dev/zero 设备文件;
另外直接打开 /dev/zero 设备文件,然后使用这个句柄创建 mmap,也是最终调用 shmem 模块创建共享匿名映射;
3. 私有文件映射
flags=MAP_PRIVATE;
常用场景是,加载动态共享库;
4. 共享文件映射
flags=MAP_SHARED;有两个应用场景;
(1) 读写文件:
内核的回写机制会将内存数据同步到磁盘;
(2) 进程间通信:
多个独立进程,打开同一个文件,互相都可以观察到,可是实现多进程通信;
核心函数如下:
1 | unsigned long mmap_region(struct file *file, unsigned long addr, |
总结:
以上的 malloc,mmap 函数,若无特别设定, 默认都是指建立虚拟地址空间,但没有建立虚拟地址空间到物理地址空间的映射;
当访问未映射的虚拟空间时,触发缺页异常,linxu 内核会处理缺页异常,缺页异常服务程序中,会分配物理页,并建立虚拟地址到物理页的映射;
补充两个问题:
- 当 mmap 重复申请相同地址,为什么不会失败?
find_vma_links() 函数便利该进程所有的 vma,当检查到当前要映射区域和已有 vma 重叠时,先销毁旧映射区,重新映射,所以第二次申请,不会报错。 - mmap 打开多个文件时,比如播放视频时,为什么会卡顿?
mmap 只是建立 vma,并未实际分配物理页面读取文件内存,当播放器真正读取文件时,会频繁触发缺页异常,再从磁盘读取文件到页面高速缓存中,会导致磁盘读性能较差;
madvise(add,len,MADV_WILLNEED|MADV_SEQUENTIAL) 对文件内容进行预读和顺序读;
但是内核默认的预读功能就可以实现;且 madvise 不适合流媒体,只适合随机读取场景;
能够有效提高流媒体服务 I / O 性能的方法是最大内核默认预读窗口;内核默认是 128K,可以通过“blockdev –setra”命令修改;
